Adding a guideline to the editor in Visual Studio介绍 我一直在寻找一种让Visual Studio在一定数量的字符后画一条线的方法。 下面是为各种版本的Visual Studio启用这些所谓的指南的指南。 Visual Studio 2013 为VS 2013安装Paul Harrington的编辑指南扩展 Visual Studio 2010和2012 VS 2010: VS 2012: 并添加一个名为 第一部分指定颜色,而另一部分( Visual Studio 2008和其他版本
如果您使用的是Visual Studio 2008,请在 只要您使用正确的路径,此技巧也适用于各种其他版本的Visual Studio:
这也适用于SQL Server 2005和其他版本。 这最初来自Sara的博客。 它也适用于几乎任何版本的Visual Studio,您只需将注册表项中的"8.0"更改为您的Visual Studio版本的相应版本号。 引导线也显示在"输出"窗口中。 (Visual Studio 2010对此进行了更正,该行仅显示在代码编辑器窗口中。) 您还可以在颜色说明符后面列出多个数字,从而在多列中提供指南:
在第4列和第80列放置一条白线。这应该是"文本编辑器"键中字符串值 务必选择可在背景上看到的线条颜色。此颜色不会显示在VS中的默认背景颜色上。这是浅灰色的值:RGB(221,221,221)。 以下是我所知道的注册表项: Visual Studio 2010:HKCU Software Microsoft VisualStudio 10.0 Text Editor Visual Studio 2008:HKCU Software Microsoft VisualStudio 9.0 Text Editor Visual Studio 2005:HKCU Software Microsoft VisualStudio 8.0 Text Editor Visual Studio 2003:HKCU Software Microsoft VisualStudio 7.1 Text Editor 对于那些运行Visual Studio 2010的用户,您可能希望安装以下扩展,而不是自己更改注册表:
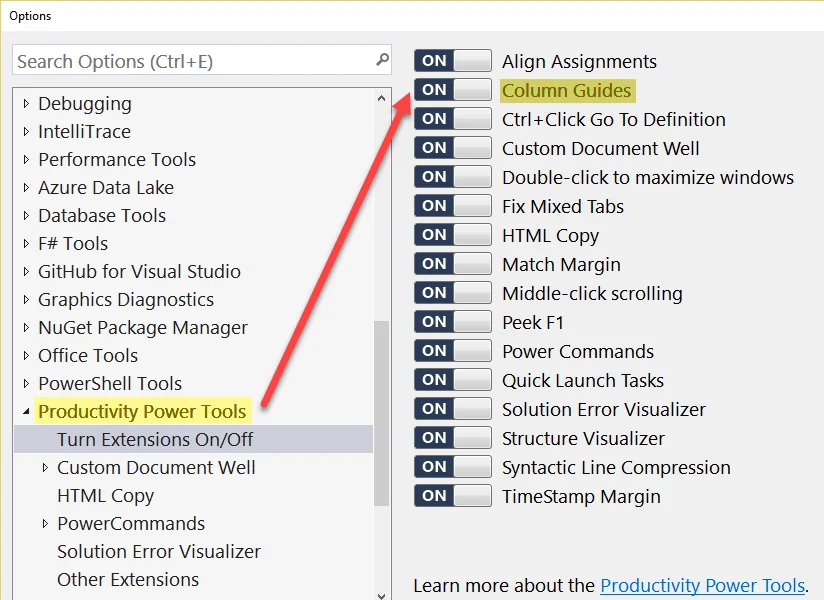
这些也是Productivity Power Tools的一部分,其中包括许多其他非常有用的扩展。 无需编辑任何注册表项,Productivity Power Tools扩展(适用于所有版本的visual studio)提供指南功能。 安装完成后,在编辑器窗口中右键单击,然后选择添加指南行选项。请注意,无论您在编辑器窗口中单击何处,指南都将始终位于编辑光标当前所在的列上。
要关闭转到选项并找到
Visual Studio 2012和2013现在有一个扩展: http://visualstudiogallery.msdn.microsoft.com/da227a0b-0e31-4a11-8f6b-3a149cf2e459 Visual Studio 2017/2019 对于寻找新版Visual Studio的答案的人,请安装Editor Guidelines插件,然后在编辑器中右键单击并选择:
如果您是免费的Visual Studio Express版本的用户,则右键是
{注意VCExpress而不是VisualStudio)但它有效! :) 这也可以在Visual Studio 2010(Beta 2)中使用,只要您安装Paul Harrington的扩展以启用VSGallery或VS2010内部的扩展管理器的指南。由于这是10.0版,因此您应该使用以下注册表项:
此外,Paul写了一个扩展,在编辑器的上下文菜单中添加条目,用于添加/删除条目,而无需直接编辑注册表。你可以在这里找到它:http://visualstudiogallery.msdn.microsoft.com/en-us/7f2a6727-2993-4c1d-8f58-ae24df14ea91 我发现了这个Visual Studio 2010扩展:缩进指南 http://visualstudiogallery.msdn.microsoft.com/e792686d-542b-474a-8c55-630980e72c30
它工作得很好。 这也适用于SQL Server Management Studio。 使用VS 2013 Express时,此密钥不存在。我看到的是HKEY_CURRENT_USER Software Microsoft VisualStudio 12.0,并且没有提到文本编辑器。 Visual Studio 2008的注册表路径是相同的,但版本号为9.0:
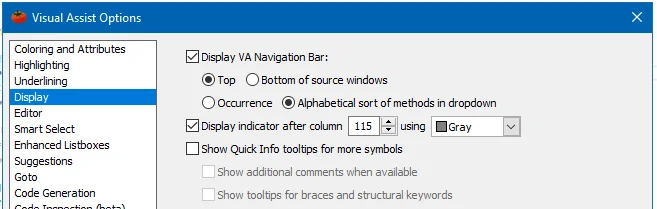
对于使用Visual Assist的用户,可以从Visual Assist选项中的
|